The Panorama X Team Server extends the reach of Panorama beyond a single computer to a network of connected computers. Using this server you can share data on a local network or even across the entire Internet.
Types of Networks
From Panorama’s point of view there are two types of networks: local networks and the internet. A local area network (LAN) is a computer network covering a small local area, like a home, office, or building. For Panorama to consider a network a local network, all of the computers on the network must be connected to a single router. Any other configuration is considered the internet.
When used on a local network, Panorama clients can use Apple’s Bonjour technology to automatically locate and connect to the Panorama X Team Server (even if there are multiple servers on the network).
When used on the internet (any non-local network), the server address (domain name or IP address) must be manually set up on each client. The process only takes a few seconds per client (similar to typing in the url in a web browser), but is not automatic.
Panorama X uses TCP/IP to communicate over both local networks and the internet.
Client/Server Modes
The Panorama X Team Server can operate in two different client/server modes: database sharing and web publishing. The mode used depends on the client software. In database sharing mode the client is Panorama itself. Database sharing mode allows you to use Panorama on your local computer in almost the same way you would with a single user database. The server coordinates data flow between multiple clients so that data can be shared seamlessly. In most cases a single user Panorama database can be converted to a shared database with almost no preparation and will continue to operate almost identically to the single user version.
In web publishing mode the client is a web browser — Safari, Google Chrome, Firefox, etc. This mode allows any authorized user on the internet to access and modify the database. Unlike database sharing mode, no copy of Panorama is required on the client computer, anyone with a web browser can join in. There are, however, some downsides to this mode. First, a database must be prepared to work in this mode. For simple applications this may take only an hour or two, while more complex applications may take hundreds of hours. Secondly, the user interface in web publishing mode is limited to the capabilities of a web browser.
Advanced Panorama features like Clairvoyance®, Smart Dates™, Lists and Matrixes, Elastic Forms, Custom Menus, Automatic Capitalization and more are not available when using a web based database. If you need universal global access to your database, however, web publishing mode is the way to go.
Database sharing mode and web publishing mode are not mutually exclusive — both modes can be in use on a single server simultaneously. In fact a single database may be used in both modes simultaneously, allowing different clients to take advantage of the appropriate mode for them. (For example you might create a product catalog database that is accessed using data sharing mode in house, while also making it publicly available in web publishing mode.)
Database Sharing Concepts and Operation
This section explains how Panorama’s database sharing mode works, and the benefits of Panorama’s unique distributed data sharing system. Traditional client/server database systems (FileMaker, SQL, etc.) store the data only on the central server computer. Panorama, in contrast, keeps copies of the data on the server but also keeps duplicate copies on every client.
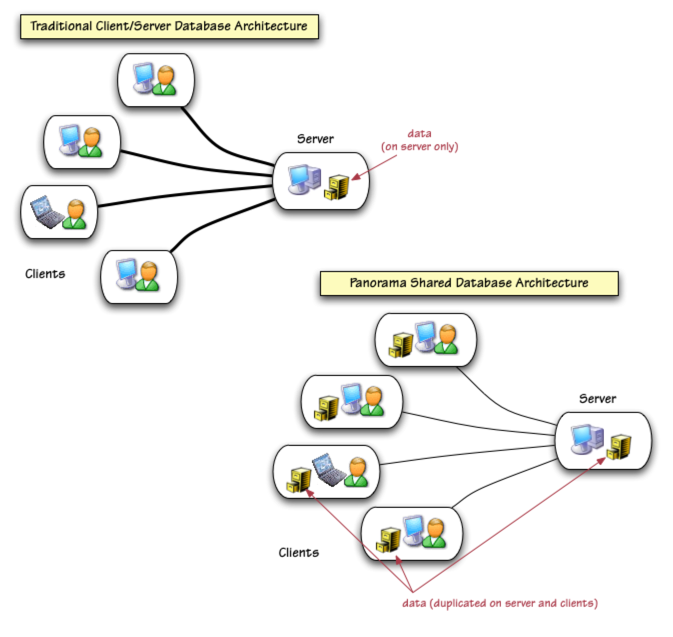
By distributing multiple copies of the data across the network, Panorama uncorks the network/server bottleneck that hampers traditional client/server database systems. Distributing the data has several key benefits over these traditional systems: high performance, low network/server load, offline operation and high safety margin. Each of these benefits is explored further in the sections below.
High Performance
When sharing a Panorama database, each client keeps a full copy of the database in RAM on the client computer. Operations like searching, sorting and reports happen almost instantaneously in RAM with no network or server delay. The server only gets involved when data is modified handling record locking and updating other clients as necessary. Traditional client/server systems, in contrast, channel every database action (query, sort, report, etc.) through the network and the server. The client is only used to display the results.
Since Panorama is RAM based, it doesn’t need or use indexes. (Indexes are special tables that disk based databases use to speed up searching and sorting.) Eliminating indexes simplifies database design, allows more flexible searching and also dramatically reduces RAM and disk requirements on each client (Panorama databases are typically much smaller than the traditional data + index tables combination — in some cases up to 90% smaller).
Low Network/Server Load
Since the network and server are not involved in a majority of database actions, the load on these components is much lower than when using a traditional client/server system. Bottom line — you’ll be able to scale to more clients without upgrading your network or server hardware.
Offline Operation
Unlike a traditional client/server database, Panorama database clients don’t go completely dark if a network connection is unavailable. Panorama’s distributed database sharing system allows off-line database browsing, searching and analysis.
High Safety Margin
Engineers understand that critical structures like bridges and aircraft must be resiliently designed to eliminate the possibility of total failure. Your data is critical to you so the Panorama X Team Server includes layered safeguards to protect every byte.
Zero-Loss Interruption Recovery
The Panorama server is RAM based for high performance, but it also keeps a disk based transaction journal for full data recovery after any kind of power failure or system interruption of any kind (the journal is a simple sequential file with minimal impact on performance). The server will automatically recover any unsaved data when the system reboots — no manual intervention is necessary.
Rebuild from any client
In a worst case scenario, Panorama’s distributed architecture provides an automatic built-in backup system. If your regular backup is unavailable (earthquake? hurricane? tsunami?) you can always rebuild the server database from the data in any client.
No delicate index to get corrupted
Since Panorama is RAM based, it doesn’t need or use indexes. In addition to the excessive space they take up, indexes have another disadvantage — they are complex and fragile structures that are easily corrupted. Although a corrupted index usually doesn’t mean the data itself is lost, a database may be offline for a considerable time while waiting for an index to be rebuilt. Since Panorama doesn’t use indexes, the possibility of a corrupted index is eliminated.
How Distributed Data Sharing Works
It’s not necessary to understand how distributed data sharing works to use the system — you can simply open your databases and access them as you normally would. If you are not interested in the details you can simply skip this section. However if you’ve used other client/server systems you might be more comfortable knowing exactly how Panorama’s distributed data sharing manages to juggle data across a network without spilling a drop. We think that the more you know about Panorama’s unique system, the more you’ll like it.
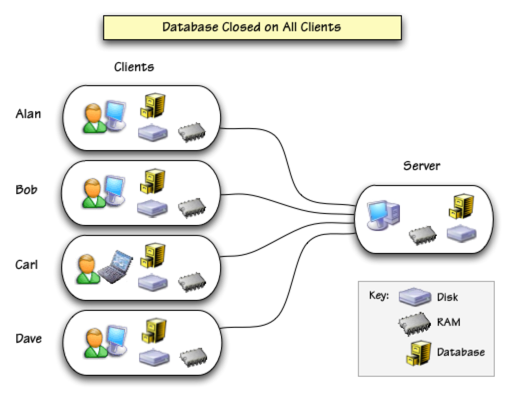
We’ll use a series of diagrams to illustrate how distributed data sharing works and how data flows across the network. Our hypothetical network contains a server and four clients: Alan, Bob, Carl and Dave. For simplicity we’ll assume that these users are only sharing a single database, which we’ll simply call the database. We start with this database all set up and ready to use, with a copy of the database on the hard drive of each client and on the server as well. (To learn how these copies are originally set up see Creating a Shared Database.)
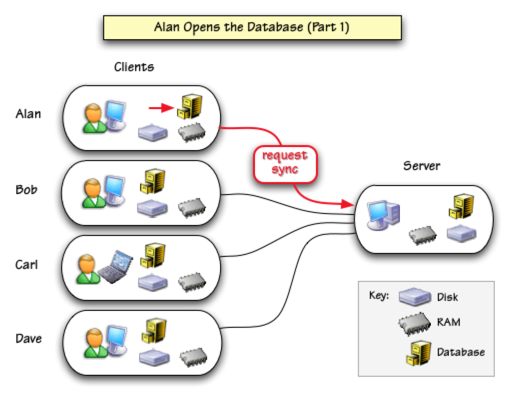
Opening a Database
The action begins as Alan double clicks on his copy of database to open it. Panorama loads the database into RAM, then contacts the server to request synchronization (more on synchronization in a moment).
In response, the server loads its copy of the database into RAM. It then gathers the most recently modified data and sends it back to Alan’s computer.
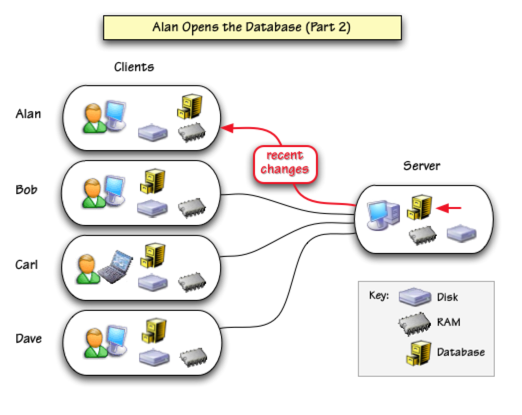
Alan’s computer takes these recent changes and updates its local copy of the database. Because Panorama is RAM based, this synchronization process is very rapid — often nearly instantaneous. Alan now has an up-to-date copy of the database available for searching, sorting, reports, etc. All of these operations are performed at blazing speed in RAM, just as it would be done if this was a single user database.
The Synchronization Process
How did the Panorama server know which changes were recent, and which changes Alan already had on his computer? And how did the Panorama client know how to merge this recently changed data with the data it already had?
Panorama keeps two invisible fields with each record in a database: ID and Time Stamp. The ID is a unique number that is assigned to the record when it is first created and never changes. The Time Stamp keeps track of when this record was last modified. (These extra fields are both invisible, and cannot be seen or modified by the user, though they can be accessed with special functions.)
Panorama also keeps an overall time stamp for each local copy of the database. This overall time stamp keeps track of when the database was last synchronized with the server. When a client requests synchronization, it passes this overall time stamp as part of the request. The server gathers all records with later time stamps (including any brand new records) and sends them back to the client. The client matches up the ID numbers to update existing records, and simultaneously adds the new records to complete the synchronization process.
A Note about Time Stamps. Time stamps are not really “clock times” in the ordinary sense of days, hours, minutes and seconds. Instead, this “time” is really a count of the total number of changes made to this database since the database was first created. Like a clock, this number always increase as time goes on. But since we don’t use a real clock, it doesn’t matter if the time is incorrectly set on one or more of your computers, or even if some of the computers are in a different time zone.
Editing and Record Locking
To edit a record, Alan double clicks a data cell in the record. Panorama sends a request to the server asking to edit the record (the request includes the record’s unique ID number). (Notice that we are assuming that Bob, Carl and Dave have now all opened this database, so the database is loaded into RAM on all four of these client machines.)
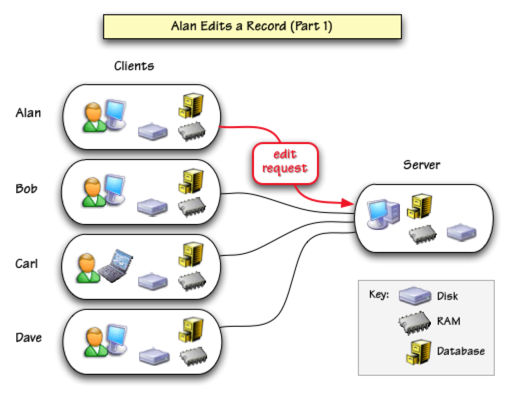
If no one else is currently editing that record, the server will respond that it is ok to edit the data. The server will also send a copy of the most up-to-date data for this record. Using this data, Panorama performs a “mini-synchronization” of just this record. This insures that the data in this record is completely up-to-date before Alan makes any changes.
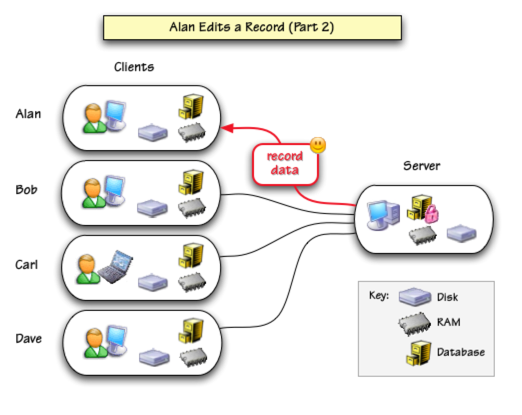
Suppose that Carl double clicks on a data cell in the same record before Alan finishes editing it? Just like before, a request is sent to the server.
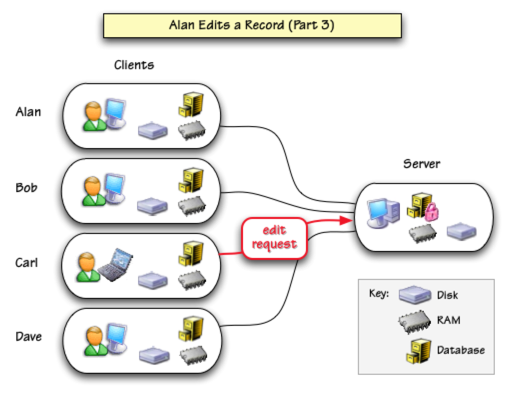
But Alan still has this record locked, so Carl’s request is denied. Carl will see an alert suggesting that he try again later. Of course Carl can edit any other record in the database.
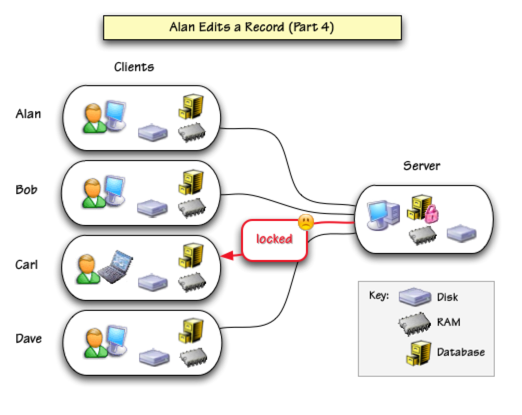
When Alan finishes editing the record (indicated by clicking on another record, clicking on another window, saving the database or simply being inactive too long) the freshly edited data is transmitted to the server.
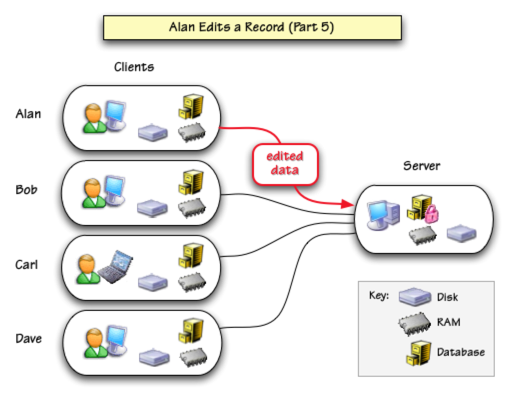
The server updates its copy of the database and releases the lock.
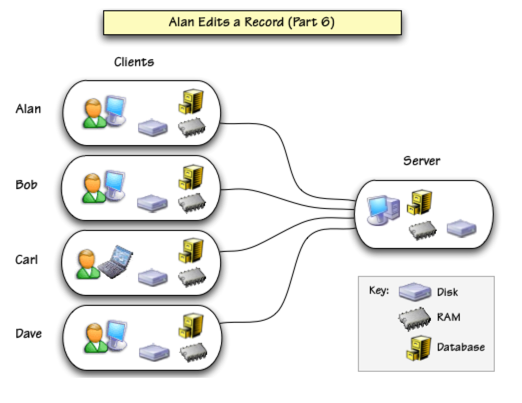
Now suppose Carl tries to edit the same record again. This time his request will succeed.
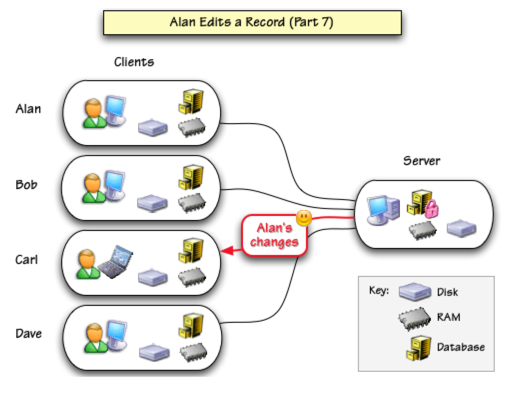
As Carl double clicks on the data cell he’ll see Alan’s changes appear before he begins editing. In some cases this can be very important. For example, suppose this is an inventory database and Alan subtracted items from a particular inventory record. Now Carl wants to subtract additional items from the same record. It’s vital that if Alan subtracted 12 and Carl now subtracts 9, the final amount will be the original amount minus 21. Because the server updates each client as the record is locked, this correct total is assured no matter how many calculations are chained together. In this example we’ve assumed that the data is being edited manually, but the same principle applies when modifications are made by a program. Whenever a record is modified it, is always locked and updated first, whether that modification is manual or done by a program.
Database Web Publishing Concepts and Operation
Like database sharing, web publishing allows a database to be viewed and accessed remotely. Instead of using a custom Panorama client, web publishing allows the database to be used by anyone with a modern web browser. This approach makes possible for a truly global audience for your database. There are, however, some downsides to using web publishing instead of database sharing. First, a database must be prepared to work in this mode. For simple applications this may take only an hour or two, while more complex applications may take hundreds of hours. Secondly, the user interface in web publishing mode is limited to the capabilities of a web browser. Advanced Panorama features like Clairvoyance®, Smart Dates™, Lists & Matrixes, Elastic Forms, Custom Menus, Automatic Capitalization and more are not available when using a web based database. If you need universal global access to your database, however, web publishing mode is the way to go.
Database sharing mode and web publishing mode are not mutually exclusive — both modes can be in use on a single server simultaneously. In fact a single database may be used in both modes simultaneously, allowing different clients to take advantage of the appropriate mode for them. (For example, you might create a product catalog database that is accessed using data sharing mode in house, while also making it publicly available in web publishing mode.)
Panorama Forms on the Web
Just as in Panorama itself, most database display and data entry on the web is accomplished through forms. You can create web forms with standard authoring tools like Dreamweaver, RapidWeaver or (assuming knowledge of HTML) a basic text editor. Panorama also includes a wizard that converts your existing Panorama forms for use on the web. This wizard allows you to use Panorama’s powerful graphic editing tools to create web based forms. The illustration below shows how this works. The screen shot on the left shows the original Panorama form. On the right is the nearly identical web based form.

Since web browsers don’t have all the capabilities available in Panorama forms, some features cannot be translated. You may find that you want to create special forms specifically for use as web forms, just as you normally create special forms for printed reports. Nevertheless, you’ll find that this capability allows you to leverage your existing skills (and much of your existing forms) to rapidly develop web based databases.
Database Tables on the Web
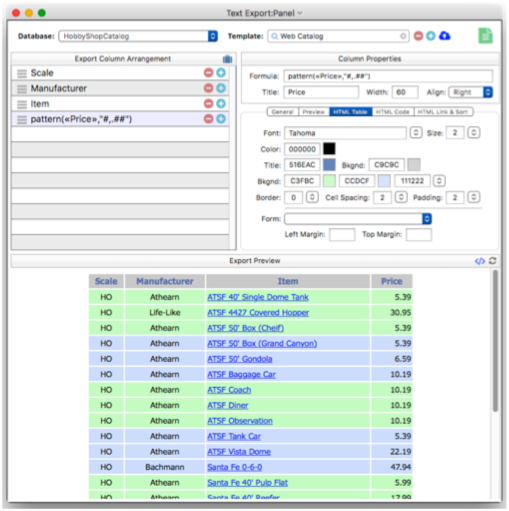
Panorama’s form conversion wizard is great for displaying one record at a time. The Text Export Wizard makes it easy to display a web page with a table showing multiple records, like this price list.
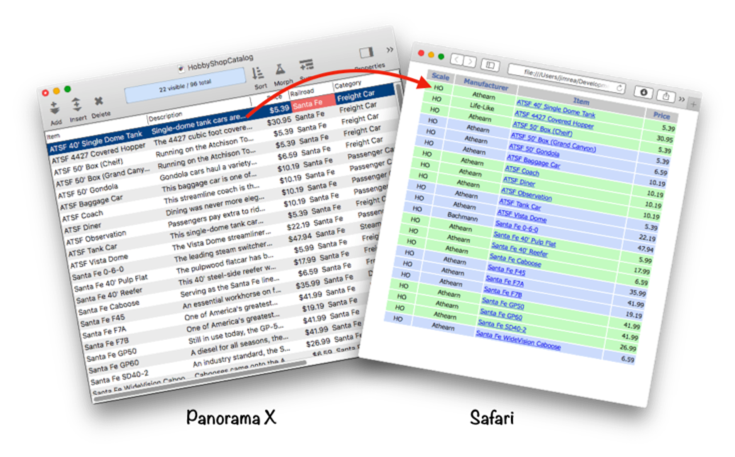
The wizard makes it easy to configure this web table in just a few minutes with no programming or HTML coding.
Custom Web Programming
The Panorama web publishing server can perform basic actions like searching the database, displaying tables, displaying forms, and data entry without any programming at all. By adding your own custom programming you can implement more advanced features. The illustration below shows a simple shopping cart based on a Panorama database. The short program displays the contents of the shopping cart.
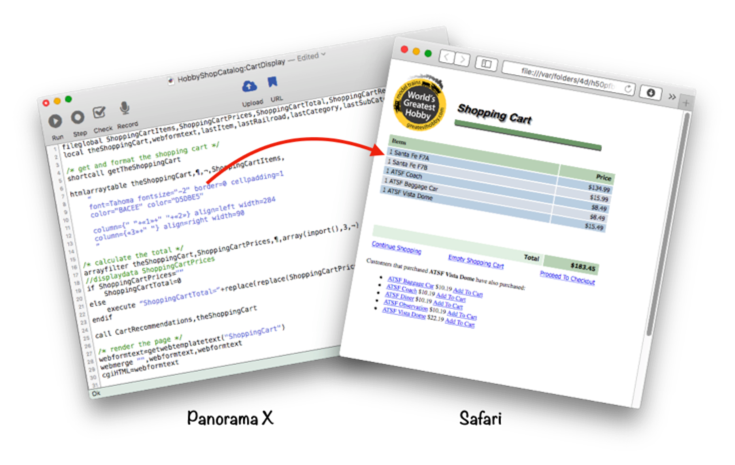
With Panorama’s powerful programming language the possibilities are limited only by your imagination!
History
| Version | Status | Notes |
| 10.2 | New | New in this version. |