The Unpropagate command (see Propagate & Unpropagate) can be used to eliminate duplicate values in a database. The first step is to click on the field that contains the potentially duplicate values, for example Name or Company. If you want to eliminate duplicates over multiple fields (for example an entire address) you must create a new field and use the Morph Field Dialog to combine the data into a single field.
To demonstrate this, we’ll remove duplicate company records from this conference registration database.
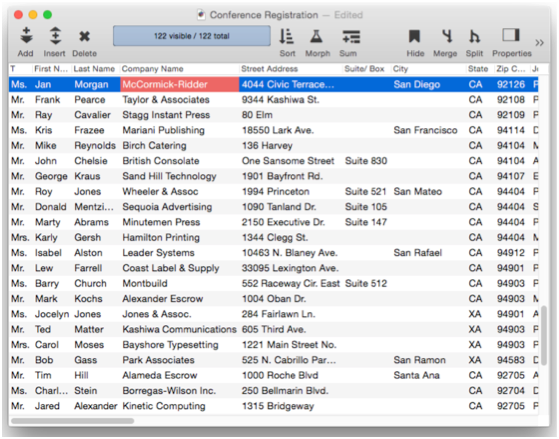
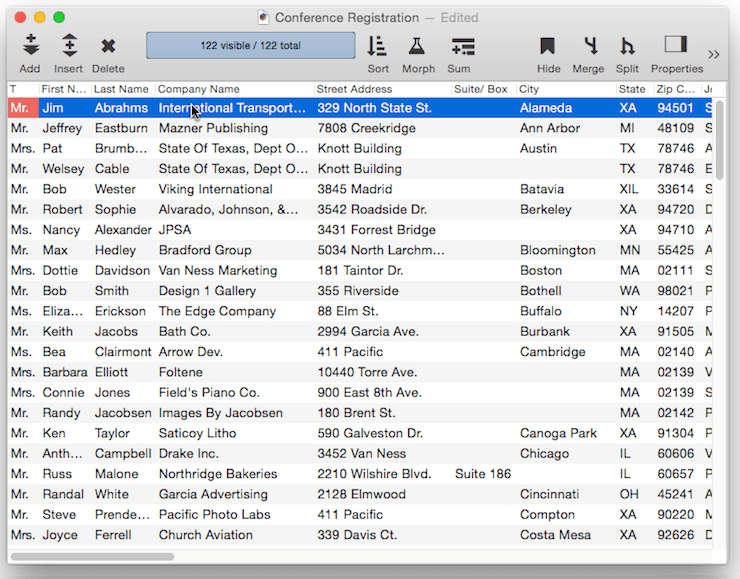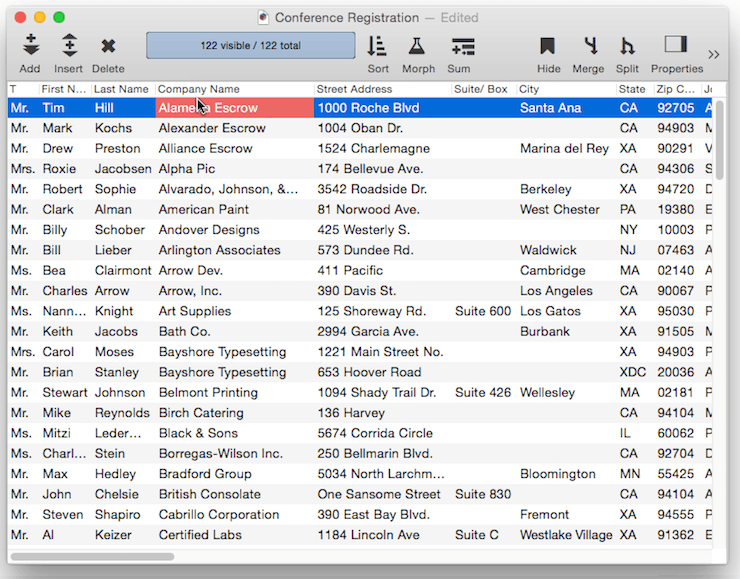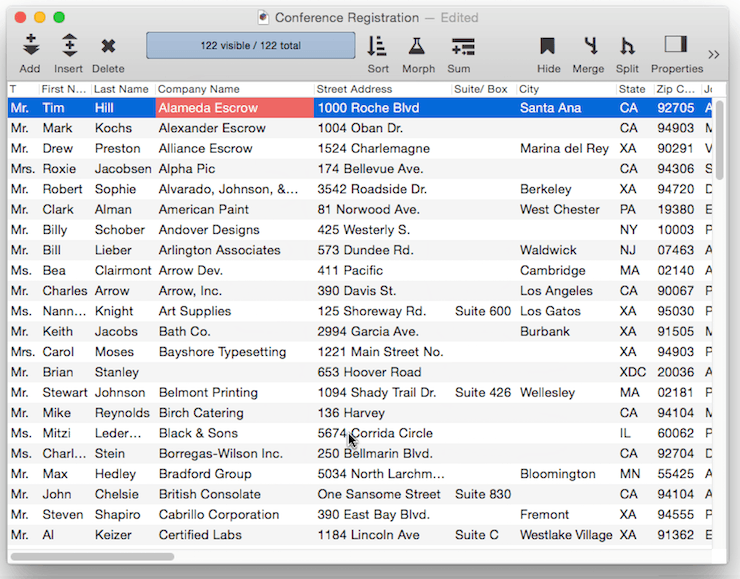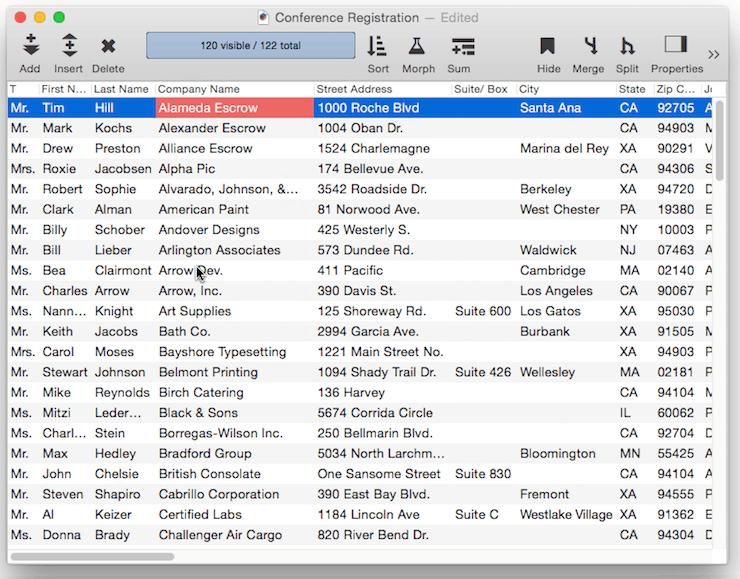
The first step is to sort up the database by company name. This brings all the duplicate values together. For example, there are two Bayshore Typesetting entries in this database.
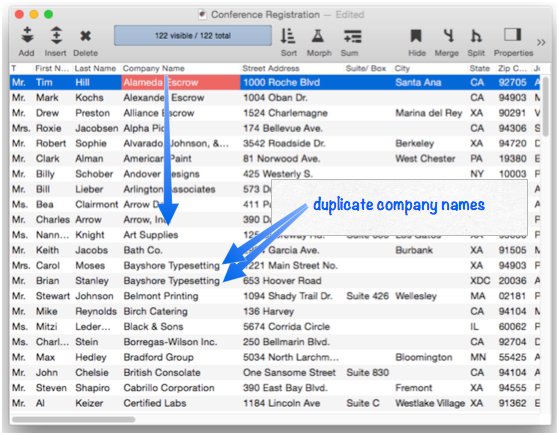
The next step is to Unpropagate the column. Wherever a duplicate value appears in the data cell, the Unpropagate operation clears the cell.
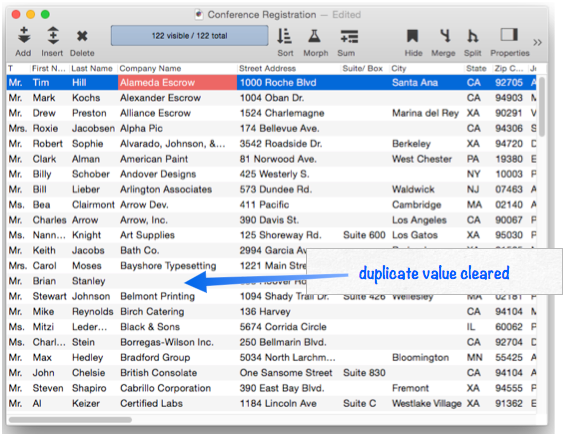
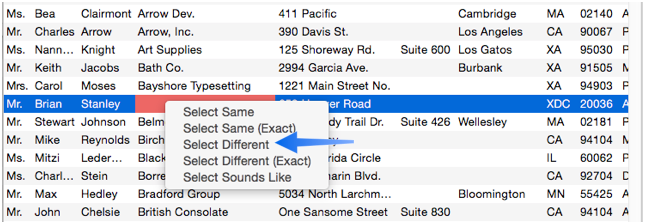
Now right click on one of the newly empty cells, and choose Select Different (see Selecting with the Context Menu).
An alternate method is to use the Find/Select Dialog to select Company Name Is Not Empty.
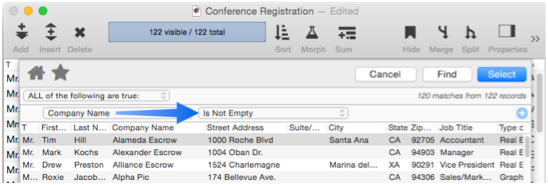
Either way, the duplicate records are now invisible.
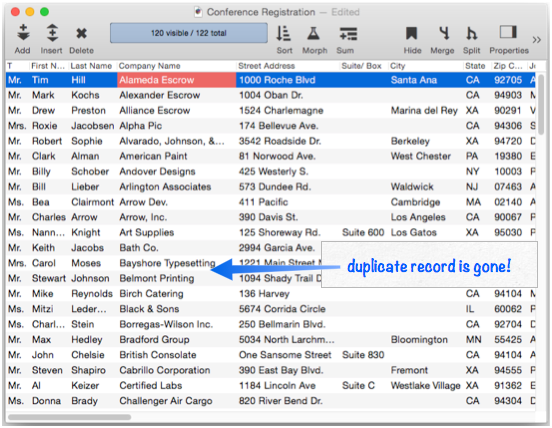
The duplicate records aren’t quite gone yet – the final step is to permanently remove the duplicate records with the Records>Delete Unselected Records command.
Here is a movie demonstrating all of the steps for removing duplicates.
Automating the Duplicate Removal Process
It’s possible to create a procedure that will automatically perform all of these steps for you. This procedure will remove all of the duplicate entries in the current field.
sortup
unpropagate
select «» <> ""
removeunselected
Tip: One possible problem with this technique is that all cells that start out empty will be removed. For example if you are removing duplicate company names but some records don’t contain company names, the records without company names will be removed. To fix this problem, use the EmptyFill statement to fill the empty names with a unique value like n/a before you start, then use the select statement to select all values not equal (≠ or <>) to n/a. Then perform the rest of the steps listed above. Here is a revised version of the procedure that takes care of this problem.
emptyfill "!empty!"
select «» <> "!empty!"
sortup
unpropagate
select «» <> ""
removeunselected
formulafill ?(«» = "!empty!" , "" , «»)
Warning: Keep in mind that all of these techniques will blindly remove all but the first duplicate entry. In this example, there were two entries for Bayshore Typesetting. However, they were probably not really duplicates, since one was in Washington, DC and the other in San Rafael, CA. There is no way for an automatic technique like this to know which of these is really correct, or even if they are really duplicates at all. If you want to manually examine duplicate records instead of blindly deleting them, use the Select Duplicates command in the Search menu.
See Also
- duplicates --
- Morph All Fields Dialog -- morphing the contents of the entire database.
- Morph Date Field Operations -- date morphing operations.
- Morph Field Dialog -- morphing the contents of an entire field.
- Morph Field Favorites -- saving and recalling favorite data morphing operations.
- Morph Numeric Field Operations -- numeric data morphing operations.
- Morph Text Field Operations -- text data morphing operations.
- morphalldialog -- opens the standard MorphAll dialog.
- morphdialog -- opens the standard Morph dialog.
- Propagate & Unpropagate -- propagating/unpropagating data within a column.
- Shifting Data Left & Right -- sliding data left and right.
- slidedata -- slides the columns at and to the right of the current column.
History
| Version | Status | Notes |
| 10.0 | No Change | Carried over from Panorama 6.0 |